Pythonの文字列は、Java等と同様にImmutableであり、頻繁に文字列を操作する場合においては、気をつけないと思わぬパフォーマンスの低下を招きます。
代表的なケースとしては、文字列に新たな文字列をどんどん連結していくケース。
s = s + "新たな文字列1"
s = s + "新たな文字列2"
s = s + "新たな文字列3"
. . .
. . .
とせずに、配列を使って、
L = []
L.append("新たな文字列1")
L.append("新たな文字列2")
L.append("新たな文字列3")
. . .
. . .
s = ''.join(L)
とするのが定石イディオムとされています(最初の例では、毎回新たな文字列が生成されるオーバーヘッドがあるとされる。参考:「Pythonクックブック」)。
これは本当に正しいのでしょうか。また、mutable文字列っぽいアプローチにはどのような方法があり、どれが一番良いのでしょうか。実際に性能を確かめてみないと納得できないので、上記の単純連結ケースについて軽く調べてみました。
代表的なケースとしては、文字列に新たな文字列をどんどん連結していくケース。
s = s + "新たな文字列1"
s = s + "新たな文字列2"
s = s + "新たな文字列3"
. . .
. . .
とせずに、配列を使って、
L = []
L.append("新たな文字列1")
L.append("新たな文字列2")
L.append("新たな文字列3")
. . .
. . .
s = ''.join(L)
とするのが定石イディオムとされています(最初の例では、毎回新たな文字列が生成されるオーバーヘッドがあるとされる。参考:「Pythonクックブック」)。
これは本当に正しいのでしょうか。また、mutable文字列っぽいアプローチにはどのような方法があり、どれが一番良いのでしょうか。実際に性能を確かめてみないと納得できないので、上記の単純連結ケースについて軽く調べてみました。
具体的には、下記のようなパターンについて、プログラムを作って、Python 2.3, 2.4, 2.5,
2.6で実行し、時間を計ってみました。(不勉強ながら、Python
3ではmutableなバイト列を扱うbytearray型が追加されているようなので、こちらも参考までに一応調べました)
パターン1. 加算演算子(+)で連結する方法
パターン2. 配列を使う方法(定石イディオム)
パターン3. mmapモジュールの無名マップを使う方法
パターン4. StringIOを使う方法
パターン5. cStringIOを使う方法
パターン6. io.StringIOを使う方法(Python 3.0, 2.6)
パターン7. bytearrayを使う方法(Python 3.0)
以下のようなソースを使い測定しました。
(注記)
- 関数すら使わない適当なコードでホントすいません。
- mmapについては、[]でアクセスする方法と、writeで書き込む方法両方試してみたところ、性能差があったので両方残しておきます。
- Python 3.0については、printやxrangeなど、上記コードをpy3k対応のため改変しました。
- Python 3.0では、mmapをスライス形式でアクセスする方法が変わっていたので、それに準拠しました。
- Python 3.0では、StringIO, cStringIOが無いため計測しませんでした。
- Python 3.0では、パターン7:bytearrayを利用するため以下のようなコードを用いました。
- Python 2.3のパターン3(無名マップ)は、やりかたがわかりませんでした(T-T)
結果は以下のようになりました(環境はIntel Core DuoのMac OS Xですので、UNIX系のOSでは同様の結果になると思われます)。単位は秒で、棒が短い方が速いことを示します。
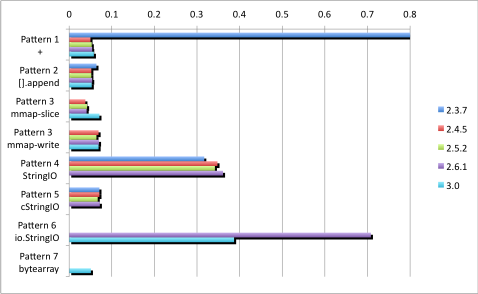
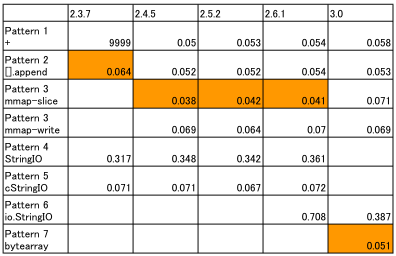
(注記)
- グラフ表示で「長時間」を表現するために2.3.7-Pattern 1の結果には「9999」を入れています。
・一番速いのは、mmapによる無名マップでスライスを使ってアクセスするアプローチのようです。仏恥義理です。ただし手軽とは言えないし、なんかずるいですよね。
・「定石イディオム」は必ずしも正しくなくなっています。Python 2.4からは、A = A + B形式の文字列連結は最適化がなされているようです。ただし、大変残念なお知らせが一つ...これらの最適化処理は、Python 2.6現在、unicode型については行われていないようです(3.0では文字列リテラルはunicode型相当なので、大丈夫)。
・総合するとやはり、定石イディオムが無難そうです。
パターン1. 加算演算子(+)で連結する方法
パターン2. 配列を使う方法(定石イディオム)
パターン3. mmapモジュールの無名マップを使う方法
パターン4. StringIOを使う方法
パターン5. cStringIOを使う方法
パターン6. io.StringIOを使う方法(Python 3.0, 2.6)
パターン7. bytearrayを使う方法(Python 3.0)
以下のようなソースを使い測定しました。
import sys
import gc
import time
TIMES = 100000
print sys.version
MAJOR_VER = float(sys.version[0:3])
if MAJOR_VER >= 2.4:
print "PATTERN 1",
start = time.time()
buf = ''
for i in xrange(0, TIMES):
buf += "a"
print (time.time() - start)
del(buf)
gc.collect()
print "PATTERN 2",
start = time.time()
L = []
for i in xrange(0, TIMES):
L.append("a")
buf = ''.join(L)
print (time.time() - start)
del(L, buf)
gc.collect()
if MAJOR_VER >= 2.4:
import mmap
print "PATTERN 3 (slice)",
start = time.time()
if MAJOR_VER < 2.6:
map_ = mmap.mmap(-1, TIMES, mmap.MAP_ANONYMOUS)
else:
map_ = mmap.mmap(-1, TIMES)
for i in xrange(0, TIMES):
map_[i] = "a"
buf = map_.read(TIMES)
map_.flush()
map_.close()
print time.time() - start
del(map_, buf)
gc.collect()
import mmap
print "PATTERN 3 (write)",
start = time.time()
if MAJOR_VER < 2.6:
map_ = mmap.mmap(-1, TIMES, mmap.MAP_ANONYMOUS)
else:
map_ = mmap.mmap(-1, TIMES)
for i in xrange(0, TIMES):
map_.write("a")
length = map_.tell()
map_.seek(0)
buf = map_.read(length)
map_.flush()
map_.close()
print time.time() - start
del(map_, buf, length)
gc.collect()
import StringIO
print "PATTERN 4",
start = time.time()
io = StringIO.StringIO()
for i in xrange(0, TIMES):
io.write('a')
buf = io.getvalue()
io.close()
print time.time() - start
del(io, buf)
gc.collect()
import cStringIO
print "PATTERN 5",
start = time.time()
io = cStringIO.StringIO()
for i in xrange(0, TIMES):
io.write('a')
buf = io.getvalue()
io.close()
print (time.time() - start)
del(io, buf)
gc.collect()
if MAJOR_VER >= 2.6:
import io
print("PATTERN 6"),
start = time.time()
io_ = io.StringIO()
for i in xrange(0, TIMES):
io_.write(u'a')
buf = io_.getvalue()
io_.close()
print time.time() - start
del(io_, buf)
gc.collect()
(注記)
- 関数すら使わない適当なコードでホントすいません。
- mmapについては、[]でアクセスする方法と、writeで書き込む方法両方試してみたところ、性能差があったので両方残しておきます。
- Python 3.0については、printやxrangeなど、上記コードをpy3k対応のため改変しました。
- Python 3.0では、mmapをスライス形式でアクセスする方法が変わっていたので、それに準拠しました。
- Python 3.0では、StringIO, cStringIOが無いため計測しませんでした。
- Python 3.0では、パターン7:bytearrayを利用するため以下のようなコードを用いました。
print("PATTERN 7", end=' ')
start = time.time()
buf = bytearray()
for i in xrange(0, TIMES):
buf += b'a'
s = buf.decode()
print((time.time() - start))
del(buf, s)
gc.collect()
- Python 2.3のパターン1は、やってみたところ終了する気配が無かったので、回避するようにしました。- Python 2.3のパターン3(無名マップ)は、やりかたがわかりませんでした(T-T)
結果は以下のようになりました(環境はIntel Core DuoのMac OS Xですので、UNIX系のOSでは同様の結果になると思われます)。単位は秒で、棒が短い方が速いことを示します。
(注記)
- グラフ表示で「長時間」を表現するために2.3.7-Pattern 1の結果には「9999」を入れています。
・一番速いのは、mmapによる無名マップでスライスを使ってアクセスするアプローチのようです。仏恥義理です。ただし手軽とは言えないし、なんかずるいですよね。
・「定石イディオム」は必ずしも正しくなくなっています。Python 2.4からは、A = A + B形式の文字列連結は最適化がなされているようです。ただし、大変残念なお知らせが一つ...これらの最適化処理は、Python 2.6現在、unicode型については行われていないようです(3.0では文字列リテラルはunicode型相当なので、大丈夫)。
・総合するとやはり、定石イディオムが無難そうです。




Leave a comment