Pythonにはじめて触って、いつのまにか1年が過ぎたのですが、一番はまったのは、やっぱりunicodeの扱いだったと思います。
特に、のようなエラーにはさんざん悩まされました。ここがたとえばrubyなど他の言語と比べてわかりにくいために、Pythonが取っつきにくい言語になっているのではないか、と個人的には思います。
そこで、このエラーに関係するはまりどころとTipsをいくつか列挙してみました。これからPythonに触れられる方の参考になればと思います。
なお、環境はUNIX上のPython 2.4, 2.5を想定しています。
特に、
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-12: ordinal not in range(128)
そこで、このエラーに関係するはまりどころとTipsをいくつか列挙してみました。これからPythonに触れられる方の参考になればと思います。
なお、環境はUNIX上のPython 2.4, 2.5を想定しています。
unicode型について
u1 = u"これはユニコード型文字列です"
のように、"の前にuをつけて宣言すると、u1は「Unicode型」になります。
u1はunicode型で、s1はstr型です。s1にどのような文字コードが格納されているかは、前節の「エンコード宣言」で何を宣言したかによって決定されます。u1には、エンコード宣言にかかわらず「Unicode文字列を表現可能な、とある内部形式」で情報が格納されています。
混乱しやすい(私が混乱した)のは、「unicode型」と、たとえば「UTF-8文字コード列」等の「Unicodeの文字列」は「別物」ということです。
str型は、代入された時点で、(ソースコードのエンコーディングがUTF-8の場合)UTF-8の文字コード列であるため、s1は、UTF-8の文字コード列としてそのまま出力することが可能です(pythonから見ると、特に意味の無いバイト列になります)。
一方、「unicode型」とは、「Unicodeを表現可能な、とある内部形式」であって、上記のu1は、どの文字コード列(エンコーディング)でもありません。どの文字コードで出力するかは、実際にu1を出力する際に決定し、出力する前に内部形式から文字コード列に変換する必要があります(これは明示的に行われることもありますし、暗黙のうちに行われることもあります)。
unicode型を使うメリット
C言語等の他の言語と同じように、日本語を単なるバイト列として扱うのであれば、unicode型を使わずに、str型に特定の文字コードのバイト列を格納してプログラムを書くことももちろん可能です。しかし、その場合、str型の変数に、どの文字コード列が格納されているのかを常に意識し、その特徴に従う必要があります。
たとえば、len関数のような、長さを返す関数は、「文字」ではなく「バイト」の長さを返すことになるので、文字コードによって長さが異なります。
正規表現もすんなりとはいきません。
さらに、Shift JISにおける0x5c問題(「表」等の文字に"\"が含まれており、エスケープコードとして扱われてしまう問題)など、気を遣わなければならない問題がたくさんあります。
このため、pythonで国際化されているライブラリやアプリケーション等では、unicode型での入出力を前提にしているものがほとんどです。パフォーマンス上の理由など、妥当な理由が存在しない限りは、pythonで日本語を扱う場合においてはunicode型を利用するのが無難です。
encode、decode、unicode
では、実際に出力する場合に、どのようにして「unicode型」を文字コード列に変換するのでしょうか。
これには、unicode型のインスタンスメソッドであるencodeを使います。その逆には、decodeを使います。
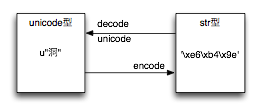
どっちがどっちだっけ?とごっちゃになったり、頭の中で逆転しやすいので、気をつけましょう。
たとえば上述のu1をUTF-8で出力するには、下記のようにします。
(ええー!python面倒くさくない?と思うなかれ。あとで、詳しく説明します)
なお、u1.encode('utf_8')は、UTF-8文字コード列(のstr型)なので、s1と同一になります。
では、s1とu1を直接比較するとどうなるのでしょうか?
標準的な環境では、こんなエラーが出ると思います。これは、(unicode型である)u1と比較するために、(str型である)s1を文字コード'ascii'でデコードしてunicode型にしようとしたのですが、できませんでした、というエラーです。
なぜ、できなかったのか?それはどの文字コードでエンコードするかが指定されていないからです。これまでのencode, decodeの例では、'utf_8'が指定されていましたが、この例では特に何も明示していません。そのため、とりあえずpythonのデフォルトの設定である'ascii'つまりASCIIコードだと想定してデコードしようとしたのですが、s1の先頭バイト(position 0)にASCIIには無い文字が出現したので、エラーとなったわけです。
pythonで日本語を使おうとすると、UnicodeEncodeError, UnicodeDecodeErrorあたりでくじけそうになります。というか私はくじけそうになりました。が、わかってしまえばたいしたことは無いので、もう少しがんばりましょう。
UnicodeDecodeErrorの原因を知る
たとえば、
のように、文字コードを省略したような場合など、「文字コードが指定されていないケースでエンコード」しなければならない局面では、encodeやstrはsys.getdefaultencoding()で取得できる、「デフォルトエンコーディング」の値を使用します。
このsys.getdefaultencoding()は通常の環境では、'ascii'になっています。
そのため、
を呼び出したときと同じ挙動をするわけです。
s1.decode()と打つと、先述のu1 == s1とまったく同じエラーが出るはずです。
(ASCIIコードだと想定してデコードしようとしたのですが、s1の先頭バイト(position 0)にASCIIには無い文字が出現したので、エラーとなった)
では、「デフォルトエンコーディング」を変えてしまえば良いのでは?getdefaultencodingがあるんだから、setdefaultencodingもあるでしょ、と思われた方は、良い勘をしていると思うんですが、setdefaultencodingは、残念ながら、ありません(*1)。
解決法としては、入力された文字列はなるべく早い段階でunicode型に変換し、その文字列は出力されるぎりぎりまでunicode型で保持するようにこころがけ、上記のような暗黙に変換されるような処理を書かないよう工夫するのがベストだと私は思います。
そのためには、どういう場所で暗黙に変換されるのか、主な「はまりどころ」を理解しておく必要があります。上記の、「str型とunicode型の比較」は「はまりどころ」の1つです。
はまりどころ:printステートメント
先ほどは、日本語を確実に出力するために、
のようにしましたが、実は、単に
ように直接unicode型を渡しても、unicode型からstr型へのエンコードが行われます。たいていは正しく日本語を出力できます。
この場合には、先ほどのsys.getdefaultencoding()で得られる文字コード(エンコーディング)ではなく、環境変数LANG等のロケールで設定された文字コードを使ってエンコードされます。
このとき使用されるエンコーディングは、sys.stdout.encodingから参照することができます。
上記のようなファイルを、nihongo.pyという名前で保存して、下記のように実行してみましょう。
LANGが日本語のときには、想定された動きをします(LANGには端末で出力できる文字コードを設定してください)。
LANGが正しく設定されていないと、上記のようにエラーが発生します。
はまりどころ:パイプ
パイプや、atやcronから起動されたプロセスなど、端末にひも付いていないプロセスからpythonを実行する場合、printステートメントにunicode型を渡すと、str型への展開にあたって、LANG等の設定は無視され、またまたsys.setdefaultencodingの値が使用されます。
単体では動くのに、パイプでつないだら動かなくなった!
単体では動くのに、cronから呼び出したら動かなくなった!
など、大いにくじける原因になりますので、注意しましょう。
はまりどころ:ファイルオブジェクトのwrite
ファイルオブジェクトのwriteは、端末にひも付いていようといまいと、ロケールを全く気にしてくれません。sys.getdefaultencoding()の値が使用されるようです。
下記のスクリプトをnihongofile.pyとして保存します。
実行します。
回避方法:sys.stdoutやファイルオブジェクトを直接使わないようにする
上記の問題点を回避するためには、printやwriteにunicode型を渡さず、str型に変換してから渡す、というのが無難な方法だと思うのですが、とはいえ、たとえばprintfデバッグをしたい場合など、unicode型を渡してしまいたいのが人情です。
安心してprintにunicode型を渡したい場合には、生のsys.stdoutではなく、streamwriterで
として、sys.stdoutをラップしてしまう方法が考えられます。
このほか、「Pythonクックブック」の1.22「標準出力にUnicodeキャラクタを出力」には、
という記法が載っていました。
([-1]がわかりにくい場合には、pydoc codecs.lookupして調べてみてください。戻り値のtupleの4番目の値、つまりStreamWriterを指しています)
sys.stdoutをファイルオブジェクトに差し替えれば、この方法は、ファイルオブジェクトでも使うことができます。
なお、出力をUTF-8で決め打ちしたくない場合には、
などとして、ロケールのエンコーディングを取得し、
のようにすると、EUC-JPやCP932な環境でも文字化けしないプログラムが書けるかもしれません。
その他:%展開
右辺にunicode型があるため、左側のstr型がunicode型にデコードされようとするが、デフォルトエンコーディングである'ascii'でデコードされようとしてしまうため、エラーになります。
右辺も左辺もstr型であるため、矛盾は生じず、エラーになりません。
%展開する文字列にuを付け忘れると、後者の例では例外が出ずに動いてしまうため、ややこしく感じることがあります。
おまけ:「エンコード宣言」
pythonのソースコード中に日本語を書く場合には、「エンコード宣言」なるものをします。具体的には「1行目か2行目に」以下のように書きます。
または
この「エンコード宣言」は、「ソースコードの文字コード」を表します。この指定は、「ソースコードの文字コード」であって、実行時の出力にも入力にも影響しません。
UnicodeDecodeErrorが出ると、この辺を疑いたくなるのですが、エディタのエンコード設定と、エンコード宣言をきちんと一致させて、あとは忘れてしまいましょう。
u1 = u"これはユニコード型文字列です"
のように、"の前にuをつけて宣言すると、u1は「Unicode型」になります。
>>> u1 = u"これはユニコード型文字列です"
>>> type(u1)
<type 'unicode'>
>>> s1 = "これはふつうの文字列です"
>>> type(s1)
<type 'str'>
混乱しやすい(私が混乱した)のは、「unicode型」と、たとえば「UTF-8文字コード列」等の「Unicodeの文字列」は「別物」ということです。
str型は、代入された時点で、(ソースコードのエンコーディングがUTF-8の場合)UTF-8の文字コード列であるため、s1は、UTF-8の文字コード列としてそのまま出力することが可能です(pythonから見ると、特に意味の無いバイト列になります)。
一方、「unicode型」とは、「Unicodeを表現可能な、とある内部形式」であって、上記のu1は、どの文字コード列(エンコーディング)でもありません。どの文字コードで出力するかは、実際にu1を出力する際に決定し、出力する前に内部形式から文字コード列に変換する必要があります(これは明示的に行われることもありますし、暗黙のうちに行われることもあります)。
unicode型を使うメリット
C言語等の他の言語と同じように、日本語を単なるバイト列として扱うのであれば、unicode型を使わずに、str型に特定の文字コードのバイト列を格納してプログラムを書くことももちろん可能です。しかし、その場合、str型の変数に、どの文字コード列が格納されているのかを常に意識し、その特徴に従う必要があります。
たとえば、len関数のような、長さを返す関数は、「文字」ではなく「バイト」の長さを返すことになるので、文字コードによって長さが異なります。
# EUC-JPなソースコードでは
>>> len("あ")
2
# UTF-8なソースコードでは
>>> len("あ")
3
# unicode型なら
>>> len(u"あ")
1
# Shift-JISなソースコードでは
>>> re.match("すも+", "すもももももももももももももももももも")
→"すも"にマッチする
# unicode型なら
>>> re.match(u"すも+", "すもももももももももももももももももも")
→"すもももももももももももももももももも"にマッチする
このため、pythonで国際化されているライブラリやアプリケーション等では、unicode型での入出力を前提にしているものがほとんどです。パフォーマンス上の理由など、妥当な理由が存在しない限りは、pythonで日本語を扱う場合においてはunicode型を利用するのが無難です。
encode、decode、unicode
では、実際に出力する場合に、どのようにして「unicode型」を文字コード列に変換するのでしょうか。
これには、unicode型のインスタンスメソッドであるencodeを使います。その逆には、decodeを使います。
- encodeは、「Unicode型を特定の文字コードのバイト列(のstr型)にエンコードする」ためのメソッドです。
- decodeは、「特定の文字コードのバイト列(のstr型)をデコードしてUnicode型にする」ためのメソッドです。
どっちがどっちだっけ?とごっちゃになったり、頭の中で逆転しやすいので、気をつけましょう。
たとえば上述のu1をUTF-8で出力するには、下記のようにします。
print u1.encode('utf_8')
なお、u1.encode('utf_8')は、UTF-8文字コード列(のstr型)なので、s1と同一になります。
>>> s1 == u1.encode('utf_8')
True
>>> s1 == u1
Traceback (most recent call last):
File "<stdin>", line 1, in ?
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe3 in position 0: ordinal not in range(128)
なぜ、できなかったのか?それはどの文字コードでエンコードするかが指定されていないからです。これまでのencode, decodeの例では、'utf_8'が指定されていましたが、この例では特に何も明示していません。そのため、とりあえずpythonのデフォルトの設定である'ascii'つまりASCIIコードだと想定してデコードしようとしたのですが、s1の先頭バイト(position 0)にASCIIには無い文字が出現したので、エラーとなったわけです。
pythonで日本語を使おうとすると、UnicodeEncodeError, UnicodeDecodeErrorあたりでくじけそうになります。というか私はくじけそうになりました。が、わかってしまえばたいしたことは無いので、もう少しがんばりましょう。
ほかに、pythonの組み込み関数unicodeも存在します。これは、主に「str型をデコードして、unicode型にする」ための組み込み関数で、(str型に対して使う限りにおいては)decodeと同じ機能を持った関数と考えられます。のように使います。u2 = unicode(s1, 'utf_8')
UnicodeDecodeErrorの原因を知る
たとえば、
u1.encode()
s1.decode()
unicode(s1)
このsys.getdefaultencoding()は通常の環境では、'ascii'になっています。
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
u1.encode('ascii')
s1.decode('ascii')
unicode(s1, 'ascii')
s1.decode()と打つと、先述のu1 == s1とまったく同じエラーが出るはずです。
>>> s1.decode()
Traceback (most recent call last):
File "<stdin>", line 1, in ?
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe3 in position 0: ordinal not in range(128)
では、「デフォルトエンコーディング」を変えてしまえば良いのでは?getdefaultencodingがあるんだから、setdefaultencodingもあるでしょ、と思われた方は、良い勘をしていると思うんですが、setdefaultencodingは、残念ながら、ありません(*1)。
解決法としては、入力された文字列はなるべく早い段階でunicode型に変換し、その文字列は出力されるぎりぎりまでunicode型で保持するようにこころがけ、上記のような暗黙に変換されるような処理を書かないよう工夫するのがベストだと私は思います。
そのためには、どういう場所で暗黙に変換されるのか、主な「はまりどころ」を理解しておく必要があります。上記の、「str型とunicode型の比較」は「はまりどころ」の1つです。
*1 正確には、python起動時に読み込まれるスクリプトで消されてしまいます。一つの解法は、setdefaultencodingが消される前に実行されるスクリプト、たとえばsitecustomize.pyで、sys.setdefaultencoding('utf_8')と書いてしまうことです。この方法については、大抵のケースを解決するものの、様々な理由からこのドキュメントでは推奨していません。興味のある方はsitecustomize.py setdefaultencodingなどのキーワードで検索してみてください。
はまりどころ:printステートメント
先ほどは、日本語を確実に出力するために、
print u1.encode('utf_8')
print u1
この場合には、先ほどのsys.getdefaultencoding()で得られる文字コード(エンコーディング)ではなく、環境変数LANG等のロケールで設定された文字コードを使ってエンコードされます。
このとき使用されるエンコーディングは、sys.stdout.encodingから参照することができます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
print sys.stdout.encoding
print u"日本語"
$ LANG=ja_JP.UTF-8 ./nihongo.py
UTF-8
日本語
$ LANG=C ./nihongo.py
ANSI_X3.4-1968
Traceback (most recent call last):
File "./nihongo.py", line 5, in ?
print u"日本語"
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-2: ordinal not in range(128)
はまりどころ:パイプ
パイプや、atやcronから起動されたプロセスなど、端末にひも付いていないプロセスからpythonを実行する場合、printステートメントにunicode型を渡すと、str型への展開にあたって、LANG等の設定は無視され、またまたsys.setdefaultencodingの値が使用されます。
単体では動くのに、パイプでつないだら動かなくなった!
単体では動くのに、cronから呼び出したら動かなくなった!
など、大いにくじける原因になりますので、注意しましょう。
$ #例1)上記のnihongo.pyを実行し、パイプに出力する
$ ./nihongo.py | cat
Traceback (most recent call last):
File "./nihongo.py", line 5, in ?
print u"日本語"
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-2: ordinal not in range(128)
None
$ #例2)LANGは無視される
$ LANG=ja_JP.UTF-8 ./nihongo.py | cat
Traceback (most recent call last):
File "./nihongo.py", line 5, in ?
print u"日本語"
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-2: ordinal not in range(128)
None
はまりどころ:ファイルオブジェクトのwrite
ファイルオブジェクトのwriteは、端末にひも付いていようといまいと、ロケールを全く気にしてくれません。sys.getdefaultencoding()の値が使用されるようです。
下記のスクリプトをnihongofile.pyとして保存します。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
f = open('fairu', 'w')
f.write(u"日本語")
$ LANG=ja_JP.UTF-8 ./nihongofile.py
Traceback (most recent call last):
File "./nihongofile.py", line 4, in ?
f.write(u"日本語")
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-2: ordinal not in range(128)
回避方法:sys.stdoutやファイルオブジェクトを直接使わないようにする
上記の問題点を回避するためには、printやwriteにunicode型を渡さず、str型に変換してから渡す、というのが無難な方法だと思うのですが、とはいえ、たとえばprintfデバッグをしたい場合など、unicode型を渡してしまいたいのが人情です。
安心してprintにunicode型を渡したい場合には、生のsys.stdoutではなく、streamwriterで
import sys, codecs
sys.stdout = codecs.EncodedFile(sys.stdout, 'utf_8')
import sys, codecs
sys.stdout = codecs.EncodedFile(sys.stdout, 'utf_8')
print u"日本語"
sys.stdout = codecs.lookup('utf_8')[-1](sys.stdout)
print u"日本語"
([-1]がわかりにくい場合には、pydoc codecs.lookupして調べてみてください。戻り値のtupleの4番目の値、つまりStreamWriterを指しています)
sys.stdoutをファイルオブジェクトに差し替えれば、この方法は、ファイルオブジェクトでも使うことができます。
f = open('fairu', 'w')
f = codecs.lookup('utf_8')[-1](f)
f.write(u"日本語")
import locale
enc = locale.getpreferredencoding()
import codecs
sys.stdout = codecs.EncodedFile(sys.stdout, enc)
その他:%展開
>>> "名前は%s、%d才です。" % (u"HDE", 12)
Traceback (most recent call last):
File "<stdin>", line 1, in ?
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe3 in position 2: ordinal not in range(128)
>>> "名前は%s、%d才です。" % ("HDE", 12)
'\xe5\x90\x8d\xe5\x89\x8d\xe3\x81\xafHDE\xe3\x80\x8112\xe6\x89\x8d\xe3\x81\xa7\xe3\x81\x99\xe3\x80\x82'
%展開する文字列にuを付け忘れると、後者の例では例外が出ずに動いてしまうため、ややこしく感じることがあります。
おまけ:「エンコード宣言」
pythonのソースコード中に日本語を書く場合には、「エンコード宣言」なるものをします。具体的には「1行目か2行目に」以下のように書きます。
# -*- coding: utf_8 -*-
# vim:fileencoding=utf_8
UnicodeDecodeErrorが出ると、この辺を疑いたくなるのですが、エディタのエンコード設定と、エンコード宣言をきちんと一致させて、あとは忘れてしまいましょう。




Leave a comment